Library cache در دیتابیس اوراکل
مطلب این پست برگرفته از Connor McDonald می باشد.
برای پردازش یک عبارت SQL ، دیتابیس اوراکل دنباله کامل تری از مراحل را انجام می دهد.
سه مرحله پردازش SQL:
۱- بررسی دستور (Syntax check) :
تأیید می کند که SQL می تواند مورد پردازش قرار گیرد.
به عنوان مثال :
SQL> select * from emp were empno = 10;
select * from emp were empno = 10
*
ERROR at line 1:
ORA-00933: SQL command not properly ended
select * from emp were empno = 10
*
ERROR at line 1:
ORA-00933: SQL command not properly ended
به دلیل غلط املایی در کلمه WHERE نمی تواند در هر پایگاه داده مبتنی بر SQL اجرا شود.
۲- بررسی معنایی (Semantic check) دستور SQL
select * from emp where empnoo = 10
از نظر دستوری صحیح است ، به این معنی که در یک دیتابیس به طور بالقوه این دستور می تواند با موفقیت اجرا شود. چک معنایی مشخص می کند که آیا این بیانیه در این پایگاه داده معتبر است – یعنی موردی که در آن پردازش می شود. در این حالت چک انجام نشد:
SQL> select * from emp where empnoo = 10;
select * from emp where empnoo = 10
*
ERROR at line 1:
ORA-00904: "EMPNOO": invalid identifier
select * from emp where empnoo = 10
*
ERROR at line 1:
ORA-00904: "EMPNOO": invalid identifier
غلط بودن ستون EMPNO بدان معنی است که دستور SQL منتقل نمی شود برای بررسی معنایی. حتی اگر عبارت SQL حاوی ستون صحیح باشد و نام جدول و سایر منابع شی نیز ورودی های معتبری در داده ها باشند، یک دستور SQL ممکن است هنوز به معنای امنیت از بررسی معنایی عبور نکند، دسترسی به آبکجت ها نیز باید مورد بررسی قرار گیرد. عدم موفقیت پرس و جو در مثال زیر:
SQL> select * from emp;
select * from emp
*
ERROR at line 1:
ORA-00942: table or view does not exist
select * from emp
*
ERROR at line 1:
ORA-00942: table or view does not exist
لزوماً نشانه عدم وجود جدول EMP نیست. ممکن است بدان معنی باشد که کاربر که می خواهد این عبارت SQL را اجرا کند از دسترسی امنیتی لازم برای مشاهده داده ها در جدول EMP برخوردار نیست.
۳- بهينه سازي (Performance)
اگر یک عبارت SQL هم از نظر دستوری و هم از نظر معنایی معتبر باشد ، در واقع می تواند در این دیتابیس اجرا شود. اما دیتابیس باید بهترین روش اجرای را تعیین کند ، تعریف “بهترین” به معنای استخراج مکانیزمی است که اجرای آن در کوتاهترین زمان پاسخ برای کاربر، کامل می شود.
۴- تولید منبع ردیف (Row source generation)
پس از تعیین بهترین گزینه اجرایی طرح بهینه ساز (optimizer plan) ، این طرح/پلن به مجموعه عملی ملموس تری برای انجام در دیتابیس تبدیل می شود. به عنوان مثال ، یک طرح بهینه ساز ممکن است از یک فهرست استفاده کند ، اما تولید منبع ردیف آن نقشه را انجام می دهد و مجموعه ای از دستورالعمل های مربوط به آن فهرست را ایجاد می کند: بلوک های جدول ، و غیره. مجموعه ای از دستورالعمل های واقعی را ایجاد می کند که در نهایت بر اجرای عبارت SQL حاکم خواهد شد.
۵- اجرا (Execution)
سرانجام ، دستور SQL آماده انجام کارهایی است که از آن خواسته شده است. موتور SQL اطلاعات منبع ردیف را به عنوان ورودی می گیرد و شروع به خواندن اطلاعات مورد نظر از دیتابیس و یا نوشتن بر روی آن می کند.
۶- نتایج فرآیند (Process results)
اگر عبارت SQL یک SELECT باشد یا حاوی یک عبارت RETURNING است، برنامه فراخوانی شده احتمالاً خروجی آن پرس و جو را مصرف می کند.
چگونه کمتر تجزیه (Parse) کنیم:
اگر یک برنامه نیاز به اجرای 10000 دستور SQL در حین کار عادی داشته باشد ، فرض معقول این است که آن 10000 دستور SQL قبل از اجرای آنها باید مراحل فوق را انجام دهد. به نظر می رسد که تجزیه (Parse) فقط هزینه ای غیرقابل اجتناب برای اجرای دستورات SQL در یک سیستم پایگاه داده رابطه ای است. برای دیگر محصولات دیتابیس رابطه ای صحیح است ، اما دو پیشرفت در دیتابیس Oracle وجود دارد که فرصت هایی را برای کم کردن میزان تجزیه (Parse) در صورت استفاده “بدون کاهش تعداد مرتبط با اجرای عبارت های SQL” فراهم می کند.
The library cache -۱
اولین فرصت بر اساس مشاهداتی است که یک برنامه ممکن است چندین عبارت SQL را چندین بار اجرا کند. ده ها کاربر ممکن است از یک عملکرد مشابه استفاده کنند ، مانند “نمایش همه فروش ها”. اگر یک عبارت SQL یک بار تجزیه شده و اثبات شده که معتبر است ، تا زمانی که دسترسی لازم برای اجرای دستور SQL در اسکیمای دیتابیس را دارد استفاده می گرددو اگر همینطور تغییر نیافته باشد اجراهای های بعدی به طور ضمنی معتبر هستند. پایگاه داده اوراکل شامل یک فروشگاه حافظه به نام کتابخانه حافظه نهان (library cache) است و هر بار که یک عبارت SQL تجزیه می شود ، دیتابیس بررسی اولیه را روی حافظه نهان (cache) انجام می دهد تا ببیند آیا آن عبارت SQL قبلاً تجزیه شده است، اگر این دستور جدید باشد یک تجزیه کامل که به عنوان “ hard parse ” نیز شناخته می شود باید انجام شود، اما اگر این دستور از قبل موجود بود با استفاده از library cache ، می توان از فعالیتهای هزینه بر hard parse جلوگیری کرد و از اطلاعات موجود در library cache از hard parse قبلی استفاده کرد.
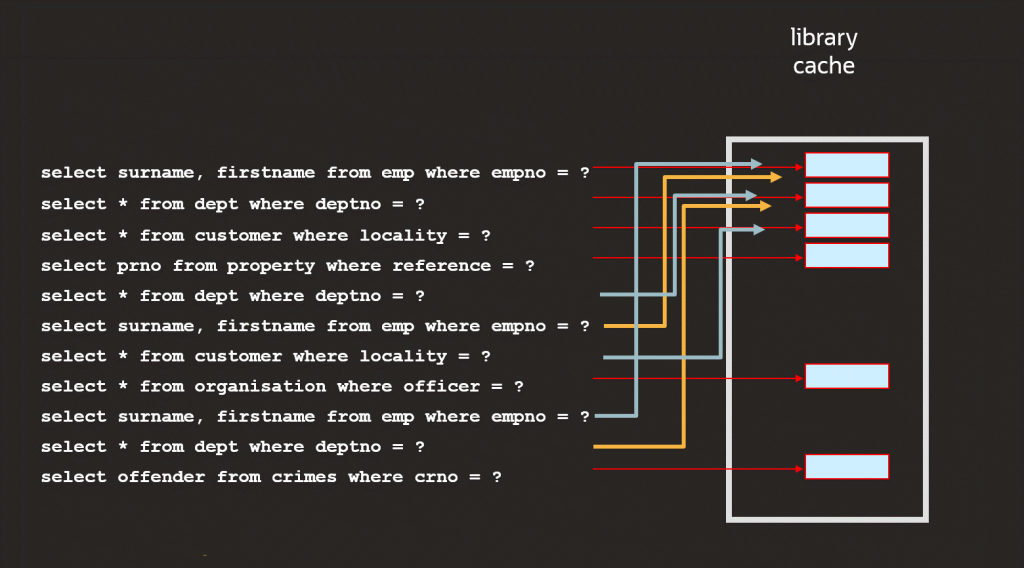
شکل زیر نمایانگر چگونگی پشتیبانی library cache از استفاده مجدد اطلاعات از یک hard parse قبلی همان عبارت SQL می باشد. 11 عبارت اجرا شده SQL وجود دارد ، اما به دلیل اجراهای مکرر همان عبارت ، از دو Parse اجتناب می شود.

دوستان زرنگ و دانا سریع خواهند گفت که با توجه به تنوع عبارات SQL موجود در یک اپلیکیشن و نیاز کاربران اپلیکیشن های شخصی برای پرس و جو از داده های مربوط به آنها ، احتمال وجود همان دستور SQL در library cache وجود دارد. بسیار کم به نظر می رسد، ولی درست است. با این حال ، به یاد بیاورید وظیفه Parse این است که: اطمینان حاصل شود که SQL یک عبارت معتبر برای پایگاه داده است که در آن اجرا می شود و تعیین یک طرح بهینه ساز مناسب برای اجرای دستور تا آنجا که ممکن است. از این منظر ، دو عبارت SQL که به صورت متنی هستند تفاوت آنها را می توان “تقریبا” یکسان در نظر گرفت.
به عنوان مثال ، این دو عبارت SQL را در نظر بگیرید:
select surname, firstname from emp where empno = 123
select surname, firstname from emp where empno = 456
select surname, firstname from emp where empno = 456